In this article I am going to explain the Implementaion of Dynamic Cube Partition in SSAS 2008. I would want to split this article in two parts as mentioned below:
In this section I will explain step by step operations to create Dynamic Cube Partitions.
STEP2:
Create new Analysis Services Project using BIDS and save it as Sales.
STEP3:
Create Data Source, and then Data Souce View using above three dimension tables.

STEP5:
Double click on the cube and navigate to Partition tab. You will see a default partition as shown below:

Delete this default partition and Click on new partition... to click new partition. In Partition Wizard, Select FactSales as available table in Specify Source Information page and click next. Select Specify a query to restict row in Restrict Rows page and write WHERE condition to restrict partition rows.

STEP10

Third Task is a sequence container which contains three task - Script Task, Analysis Services Execute DDL Task, and Execute SQL Task.
Script Task is used for two reasons -
1. To check whether current partition exists or not.
2. To update XMLA content for current Partition.
This is the most tricky and interseting part here. We need to replace Partition ID, Partition Name, and Source QueryDefinition for current Partition which are highlighted below:

In Script Task, select User::FromDateKey,User::PartitionName,User::ToDateKey as ReadOnlyVariables and User::CreatePartitionXMLA,User::ProcessPartitionXMLA,User::IsPartitionExists as ReadWriteVariables.
Click here to download the code for Script Task - Generate XMLA to create and Process new Partition.
Click SSIS Script Task to Find and Replace File contents to know more about find and replace mechanism using script task.
Second task in the sequence Container is Analysis Services Execute DDL Task. This task is used to create new Partition. In Analysis Services Execute DDL Task Editor, select SSAS.localhost as Connection, Variable as SourceType, and User::CreatePartitionXMLA as Source.
Also don't forget to set precedence constraint. You should execute this task only when partition does not exists. Open Precedence Constraint Editor and Select Expression and Constraint in Evolution operation, Success in Value, and @IsPartitionExists == 0 in Expression as shown below:

Third Task in the Sequence Container is Execute SQL Task - this is used to store newly created Partition information in the PartitionLog table. In Execute SQL Task, select ResultSet None, ConnectionType OLE DB, Connection (local).Test, SQLSourceType Direct input and SQLStatement as:
INSERT INTO dbo.PartitionLog
([PartitionName],[FromDateKey],[ToDateKey],[CreatedDate])
VALUES (?,?,?,GETDATE())
Click on Parameter Mapping and map the parameters as shown below:

STEP11
Finally we need to process the current partition. This is independent of previous sequence container where we are creating new partition if it is not exists.
However, we need to process the current partition every time we execute the package. In most of the cases, new partition will be created on the first day of month but partition should be processed everyday to include delta data.
This sequence container also contains three tasks.
First task is Analysis Services Processing Task - to process the dimensions data. Select SSAS.localhost as connection manager and all the dimensions in Object Name - which are not static in data. Select Process Update as Process Option.

Second Task is againg Analysis Serives Processing Task - to process Current Partition. Select SSAS.localhost as connection manager and Sales_20100101-20100131 in Object Name - which is default partition (or first partition). Select Process Full as Process Option.
 Now click on Expression and select @[User::ProcessPartitionXMLA] in ProcessingCommands.
Now click on Expression and select @[User::ProcessPartitionXMLA] in ProcessingCommands.
Finally store the Last Processed Date and Processed Count (number of time this partition has processed) in the log table using Execute SQL task. Select ResultSet None, ConnectionType OLE DB, Connection (local).Test, SQLSourceType Direct input and SQLStatement as:
UPDATE PartitionLog
SET LastProcessDate = GETDATE()
,ProcessedCount = ProcessedCount + 1
WHERE PartitionName = ?
Click on Parameter Mapping and map the parameters and map the parameter 0 with User::PartitionName.
STEP12
We are done with package development. Now its time to execute the package and check the dynamic behaviour of Partition creation and processing. Before execution the package, there is only partition in the SSAS Sale database.
Now Right Click on the package and execute it. Once package is execute successfully, you will see one more partition in the Sales database and one more entry in PartitionLog table.





We are done with Dynamic Package creation.
I hope you will like this article and if your answer is yes then don't forget to click Like :-)
Many people have had asked me to share the solution. I have stored that in my SkyDrive so you can download it from here: Dynamic Cube Partition
Cheers!!!
- Partition benefits
- Implementing Dynamic Partitions
- Better Query Performance: Cube partition is a powerful mechanism for improving query performance. Queries that summarize data over 10 years could take considerably longer than those that only search through the current year data. If we have proper partitions then SSAS only has to scan a small subset of data to return query results hence dramatic performance improvements compared to queries running against a cube with a single partition.
- Minimize downtime: Cube partitioning supports reducing downtime associated with cube processing. In almost all the cases, a portion of data warehouse is volatile and needs to be processed often. However other portions are relatively static. For example, in a sales cube, we need to change the current year's data nightly, but sales from previous years might change only occasionally - in case if account for merchandise returns and exchanges. If your warehouse tracks last 10 years salesthen processing only the current partition may be 10 times quicker than processing the entire cube.
- Aggregations benefits: The partition queried frequently could benefit from additional aggregations, which in turn could improve performance. Partition(s) that are used less can be processed less frequently with considerably fewer aggregations.
- Customized storage and processing settings: Frequently accessed partitions might benefit from proactive caching and ROLAP storage. On the other hand, other forms of storage and processing might be better for less frequently queried partitions.
- Distributed query and processing load: SSAS allows you to create remote partitions - a remote partition resides on a server different from its parent cube. This way the queries that affect the remote partition are processed on a server separate from its parent cube, allowing you to take advantage of additional processing power.
- Parallel Partitions Processing: SSAS allows processing multiple partitions in parallel on a server that has multiple processors. This can further reduce the total cube processing time.
Implementing Dynamic Partitions
STEP1:
Preapare test data for Sales cube. I will use three dimensions (DimDate, DimProduct, and DimCustomer) and one fact table for Sales cube. Click here to download CubePartitionData.sql file which contains T-SQL code to generate these tables along with sample data.
Preapare test data for Sales cube. I will use three dimensions (DimDate, DimProduct, and DimCustomer) and one fact table for Sales cube. Click here to download CubePartitionData.sql file which contains T-SQL code to generate these tables along with sample data.
STEP2:
Create new Analysis Services Project using BIDS and save it as Sales.
STEP3:
Create Data Source, and then Data Souce View using above three dimension tables.

If you are newbie, click Creating First Cube in SSAS 2008 for more information.
STEP4:
Create Sales cube along with required dimensions. Set all required properties of dimensions and create any hierarchies if required. My Solution looks like this:

STEP4:
Create Sales cube along with required dimensions. Set all required properties of dimensions and create any hierarchies if required. My Solution looks like this:

STEP5:
Double click on the cube and navigate to Partition tab. You will see a default partition as shown below:


Click Next twice and enter Partition name Sales_20100101-20100131 in the Completing the Wizard page and click Finish.
Finally Process the cube. Once cube is processed successfully, you can see a new database in Analysis Services:

Finally Process the cube. Once cube is processed successfully, you can see a new database in Analysis Services:

You can browse the data for this partition:

STEP6:
We are done with one manual partition. Now its time to create the partitions dynamically and apply a logic to process the delta data every time.
First off all, right click on the Partition Sales_20100101-20100131 (highlighted above) and then select Script Partition as ==> Create To ==> New Query Editor Window. It will create XMLA scripts for this partition. Save this file in the project with CreatePartitionSales_20100101-20100131.xmla name.
In similar fashion, right click on the Partition Sales_20100101-20100131 and then select Process. This will open Process Partition wizard, click Script to generate XMLA script and save this file in the project with CreatePartitionSales_20100101-20100131.xmla name.
STEP7:

STEP6:
We are done with one manual partition. Now its time to create the partitions dynamically and apply a logic to process the delta data every time.
First off all, right click on the Partition Sales_20100101-20100131 (highlighted above) and then select Script Partition as ==> Create To ==> New Query Editor Window. It will create XMLA scripts for this partition. Save this file in the project with CreatePartitionSales_20100101-20100131.xmla name.
In similar fashion, right click on the Partition Sales_20100101-20100131 and then select Process. This will open Process Partition wizard, click Script to generate XMLA script and save this file in the project with CreatePartitionSales_20100101-20100131.xmla name.
STEP7:
We are done with SSAS development! Now we have to create an SSIS package to implement dynamic creation of cube partition and processing of that partition.
Click on File => Add => New Project in menu bar in the same solution. Select Integration Services Project and enter the name of the SSIS Project.
Rename the SSIS package1.dtsx by DynamicSalesPartition.dtsx.
STEP8:
Add two connection Managers - one OLE DB connection manager for database and another Analysis Services connection manager for SSAS database.
 STEP9:
STEP9:
Add following Package variables:

FromDateKey - To Store current partition start date key e.g. 20101201.
ToDateKey - To Store current partition end date e.g. 20101231
PartitionName - Current partition name e.g. SalesPartition_20101201-20101231
IsPartitionExists - To check whether partition alreday exists or not
CreatePartitionXMLA - To store XMLA script to create current partition
ProcessPartitionXMLA- To store XMLA script to process current partition
Click on File => Add => New Project in menu bar in the same solution. Select Integration Services Project and enter the name of the SSIS Project.
Rename the SSIS package1.dtsx by DynamicSalesPartition.dtsx.
STEP8:
Add two connection Managers - one OLE DB connection manager for database and another Analysis Services connection manager for SSAS database.
Add following Package variables:

Here is the brief description of each variable:
Directory - To store package pathFromDateKey - To Store current partition start date key e.g. 20101201.
ToDateKey - To Store current partition end date e.g. 20101231
PartitionName - Current partition name e.g. SalesPartition_20101201-20101231
IsPartitionExists - To check whether partition alreday exists or not
CreatePartitionXMLA - To store XMLA script to create current partition
ProcessPartitionXMLA- To store XMLA script to process current partition
Note: You can add more variables as per need and business requirement.
STEP10
Now you have to develop SSIS package as shown below:

First Execute SQL Task is used to initialize FromDateKey, ToDateKey, and PartitionName for the current partition. Use below query in this Task:
DECLARE
@FromDateKey varchar(8), @ToDateKey varchar(8),
@CalendarYear int, @CalendarMonth int
SELECT
@FromDateKey = MAX(FromDateKey),
@ToDateKey = MAX(ToDateKey)
FROM PartitionLog (NOLOCK)
SELECT
@CalendarYear = MIN(CalendarYear),
@CalendarMonth = MIN(CalendarMonth)
FROM DimDate WHERE DateKey > @ToDateKey + 1
--SET FromDateKey and ToDateKey for current Partition
IF NOT CONVERT(varchar(8),GETDATE(),112) BETWEEN @FromDateKey AND @ToDateKey
SELECT @FromDateKey = MIN(DateKey), @ToDateKey = MAX(DateKey)
FROM DimDate (NOLOCK)
WHERE CalendarYear = @CalendarYear AND CalendarMonth = @CalendarMonth
SELECT @FromDateKey AS FromDateKey, @ToDateKey AS ToDateKey,
'Sales_' + @FromDateKey + '-' + @ToDateKey AS PartitionName
GO
DECLARE
@FromDateKey varchar(8), @ToDateKey varchar(8),
@CalendarYear int, @CalendarMonth int
SELECT
@FromDateKey = MAX(FromDateKey),
@ToDateKey = MAX(ToDateKey)
FROM PartitionLog (NOLOCK)
SELECT
@CalendarYear = MIN(CalendarYear),
@CalendarMonth = MIN(CalendarMonth)
FROM DimDate WHERE DateKey > @ToDateKey + 1
--SET FromDateKey and ToDateKey for current Partition
IF NOT CONVERT(varchar(8),GETDATE(),112) BETWEEN @FromDateKey AND @ToDateKey
SELECT @FromDateKey = MIN(DateKey), @ToDateKey = MAX(DateKey)
FROM DimDate (NOLOCK)
WHERE CalendarYear = @CalendarYear AND CalendarMonth = @CalendarMonth
SELECT @FromDateKey AS FromDateKey, @ToDateKey AS ToDateKey,
'Sales_' + @FromDateKey + '-' + @ToDateKey AS PartitionName
GO
Second Task in the package is Script Task. Here we need to read the contents of files
CreatePartitionSales_20100101-20100131.xmla and
ProcessPartitionSales_20100101-20100131.xmla and store in the package variables CreatePartitionXMLA & ProcessPartitionXMLA.
I am using User::Directory as ReadOnlyVariable and User::CreatePartitionXMLA,User::ProcessPartitionXMLA as ReadWriteVariables.
Click here to download the code for Script Task - Read XMLA Files and store in variables.
To know about reading file contents using Script Task, click Script Task to Read File.
CreatePartitionSales_20100101-20100131.xmla and
ProcessPartitionSales_20100101-20100131.xmla and store in the package variables CreatePartitionXMLA & ProcessPartitionXMLA.
I am using User::Directory as ReadOnlyVariable and User::CreatePartitionXMLA,User::ProcessPartitionXMLA as ReadWriteVariables.
Click here to download the code for Script Task - Read XMLA Files and store in variables.
To know about reading file contents using Script Task, click Script Task to Read File.
Third Task is a sequence container which contains three task - Script Task, Analysis Services Execute DDL Task, and Execute SQL Task.
Script Task is used for two reasons -
1. To check whether current partition exists or not.
2. To update XMLA content for current Partition.
This is the most tricky and interseting part here. We need to replace Partition ID, Partition Name, and Source QueryDefinition for current Partition which are highlighted below:

Click here to download the code for Script Task - Generate XMLA to create and Process new Partition.
Click SSIS Script Task to Find and Replace File contents to know more about find and replace mechanism using script task.
Second task in the sequence Container is Analysis Services Execute DDL Task. This task is used to create new Partition. In Analysis Services Execute DDL Task Editor, select SSAS.localhost as Connection, Variable as SourceType, and User::CreatePartitionXMLA as Source.
Also don't forget to set precedence constraint. You should execute this task only when partition does not exists. Open Precedence Constraint Editor and Select Expression and Constraint in Evolution operation, Success in Value, and @IsPartitionExists == 0 in Expression as shown below:

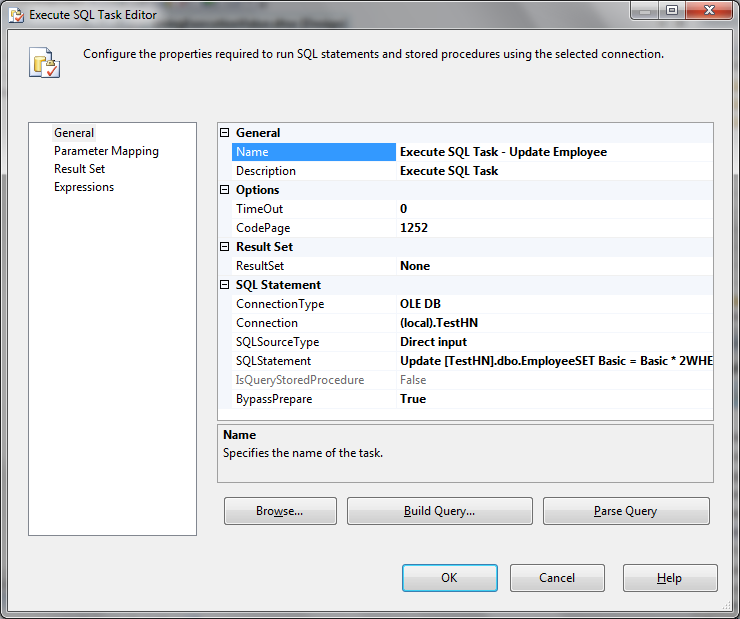
Third Task in the Sequence Container is Execute SQL Task - this is used to store newly created Partition information in the PartitionLog table. In Execute SQL Task, select ResultSet None, ConnectionType OLE DB, Connection (local).Test, SQLSourceType Direct input and SQLStatement as:
INSERT INTO dbo.PartitionLog
([PartitionName],[FromDateKey],[ToDateKey],[CreatedDate])
VALUES (?,?,?,GETDATE())
Click on Parameter Mapping and map the parameters as shown below:

STEP11
Finally we need to process the current partition. This is independent of previous sequence container where we are creating new partition if it is not exists.
However, we need to process the current partition every time we execute the package. In most of the cases, new partition will be created on the first day of month but partition should be processed everyday to include delta data.
This sequence container also contains three tasks.
First task is Analysis Services Processing Task - to process the dimensions data. Select SSAS.localhost as connection manager and all the dimensions in Object Name - which are not static in data. Select Process Update as Process Option.

Second Task is againg Analysis Serives Processing Task - to process Current Partition. Select SSAS.localhost as connection manager and Sales_20100101-20100131 in Object Name - which is default partition (or first partition). Select Process Full as Process Option.

Finally store the Last Processed Date and Processed Count (number of time this partition has processed) in the log table using Execute SQL task. Select ResultSet None, ConnectionType OLE DB, Connection (local).Test, SQLSourceType Direct input and SQLStatement as:
UPDATE PartitionLog
SET LastProcessDate = GETDATE()
,ProcessedCount = ProcessedCount + 1
WHERE PartitionName = ?
Click on Parameter Mapping and map the parameters and map the parameter 0 with User::PartitionName.
We are done with package development. Now its time to execute the package and check the dynamic behaviour of Partition creation and processing. Before execution the package, there is only partition in the SSAS Sale database.
Now Right Click on the package and execute it. Once package is execute successfully, you will see one more partition in the Sales database and one more entry in PartitionLog table.


Now Execute the package or schedule it to execute automatically. Once you are done with 10 more executions, you will reach to current month partition Sales_20101201-20101231. and you can see 12 partitions - one partition for each month as shown below:

Since you are in current month partition, if you execute the package every day in current month - it will not create any new partition till beginning of next month. It will only process Current Partition to include the data in the cube as shown below:

Now you can browse the data for all the partitions:

We are done with Dynamic Package creation.
I hope you will like this article and if your answer is yes then don't forget to click Like :-)
Many people have had asked me to share the solution. I have stored that in my SkyDrive so you can download it from here: Dynamic Cube Partition
Cheers!!!